《操作系统概念》第九章笔记 1
引入 | Introduction
「进程的代码等数据必须在内存中」,这是因为 CPU 只有能力访问内存,而并不能访问磁盘。但是,在上一节的末尾我们提出了 swapping 机制,这一机制允许我们把那些在 [[main memory]] 里放不下的内容交换到 disk 里。这一机制其实扩展了「内存」的概念:在这种机制的支持下,我们并不需要顾虑内存的实际大小;物理内存和用于交换的磁盘空间一并被用来提供「内存」的作用,也就是给操作系统提供按照地址访问内存单元中数据的能力。
然而,虚拟内存的实现并不容易,使用不当可能会降低性能。
背景 | Background
虚拟内存将用户逻辑内存与物理内存分开,使得编程更加容易,不用关注具体的物理地址(关注了也没用,每次都不一样)。
虚拟地址空间就是进程如何在内存中存放的逻辑,物理地址按帧组织,并且分配给进程的物理帧也可以不连续,需要 内存管理单元(MMU) 将逻辑页映射到内存的物理页帧。
随着动态内存的分配,允许堆向上增长,同时随着子程序不断调用,允许栈向下生长。下图是采用虚拟内存的共享库,这样做可以有效加快内存的访问速度。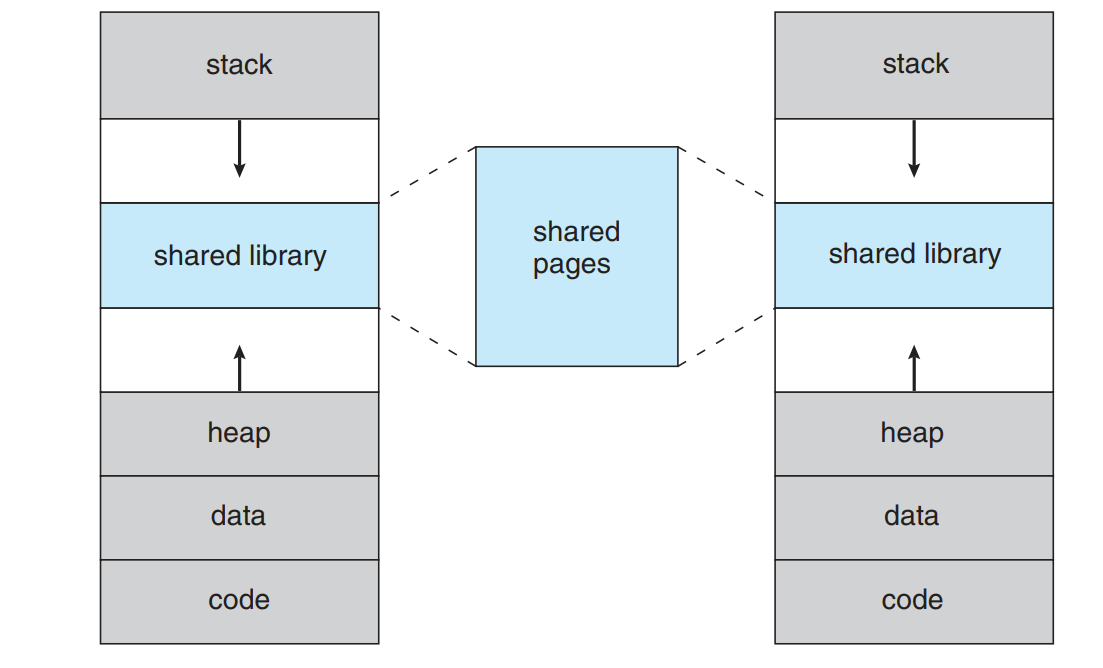
请求调页 | Demand Paging
加载整个程序会导致所有选项的执行代码都处在内存,不管其是否被使用,这显然不节约,开销很大。因此更符合直觉的是,只有在需要的时候加载页面,这种技术叫做请求调页。
请求调页时,进程驻留在外存上,通常是磁盘,当进程需要执行的时候,被交换到内存中,然而不是把整个进程交换,只把需要的页面交换进去,这种交换叫做惰性交换
基本概念 | Basic Concept
换入进程时,调页程序猜测该进程在换出之前需要用到哪些页,把要使用的页调入内存。(由于不知道甲方需求只能先猜着)
在上一章的5.3节Protection一章中我们提到过一种页面有效无效的表示方式,当页面设置为有效时,相关联页面合法,内存有效。无效啥的就不用说了。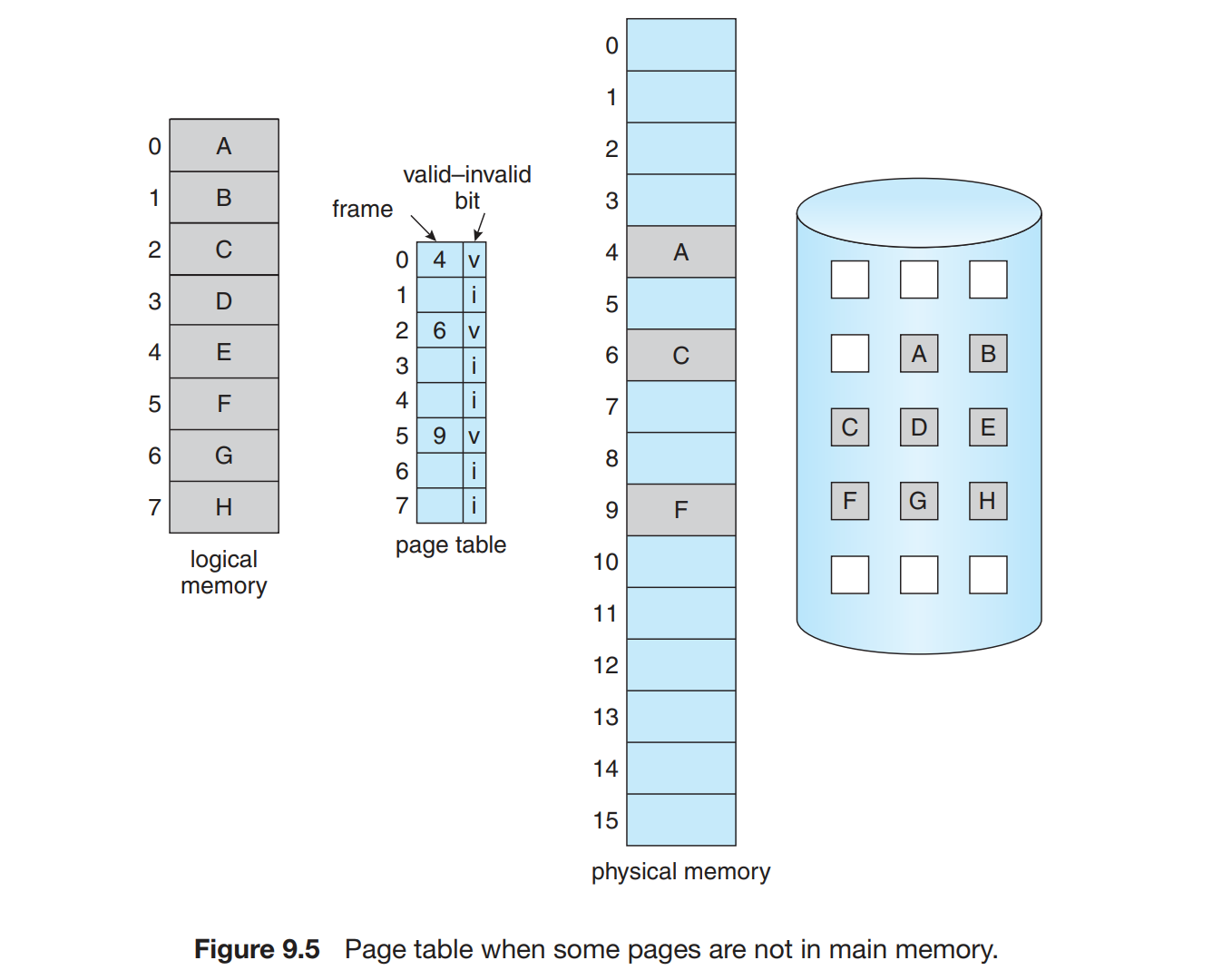
我劝同志们多背点单词,免得 valid 和 invalid 摆在面前却不知道什么意思
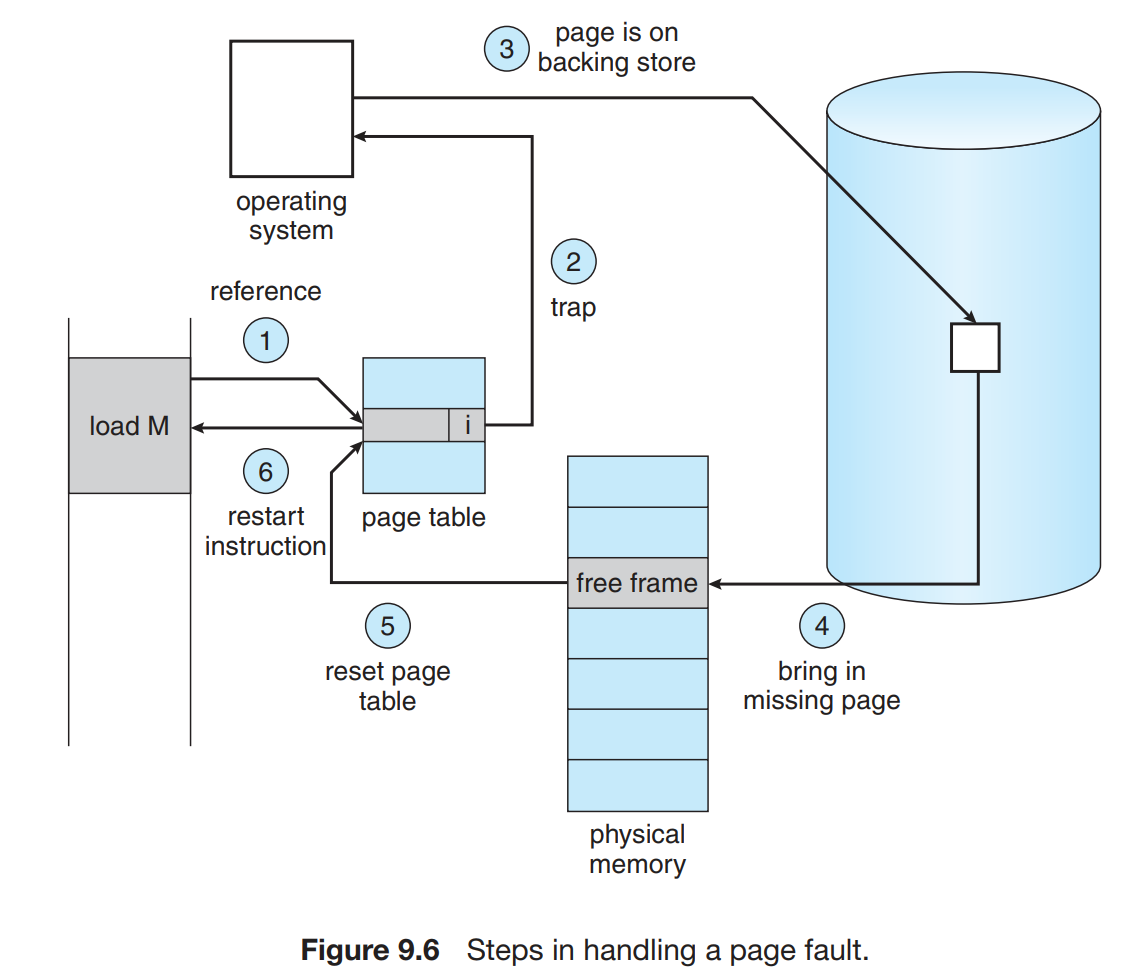
在处理缺页错误的处理方法,认为中文翻译的较不准确,故采用英文的说法。
请求调页的关键要求是拥有在缺页错误后重新启动任何指令的能力,比如,ADD这个汇编指令有3个地址指令ABC,在存储A+B的和到C时调页错误,则调页后需要重新加载ADD和ABC三个地址,重复。
请求调页的性能 | Performance of Demand Paging
请求调页会显著影响计算机的性能,因此需要计算请求调页时的有效访问时间
有效访问时间 = (1-p) ma + p 缺页错误时间
其中 p 为缺页错误的概率
增加请求调页性能最重要的就是:降低缺页错误率
写时复制 | Copy-on-Write
写时复制(Copy-on-Write)的技术允许父进程和子进程最初共享相同的页面工作,这些共享页面标记为写时复制。
这种技术可以会想到我们在进程那一章提到的fork语句,用fork创建父进程的一个复制,然而许多子进程在创建之后立即系统调用 exec() 父进程地址空间的复制没有必要,用页面共享绕过了请求调页的请求,提供了快速的创建进程。
把写时复制的共享页面,如果有进程访问页,就创建该页的副本。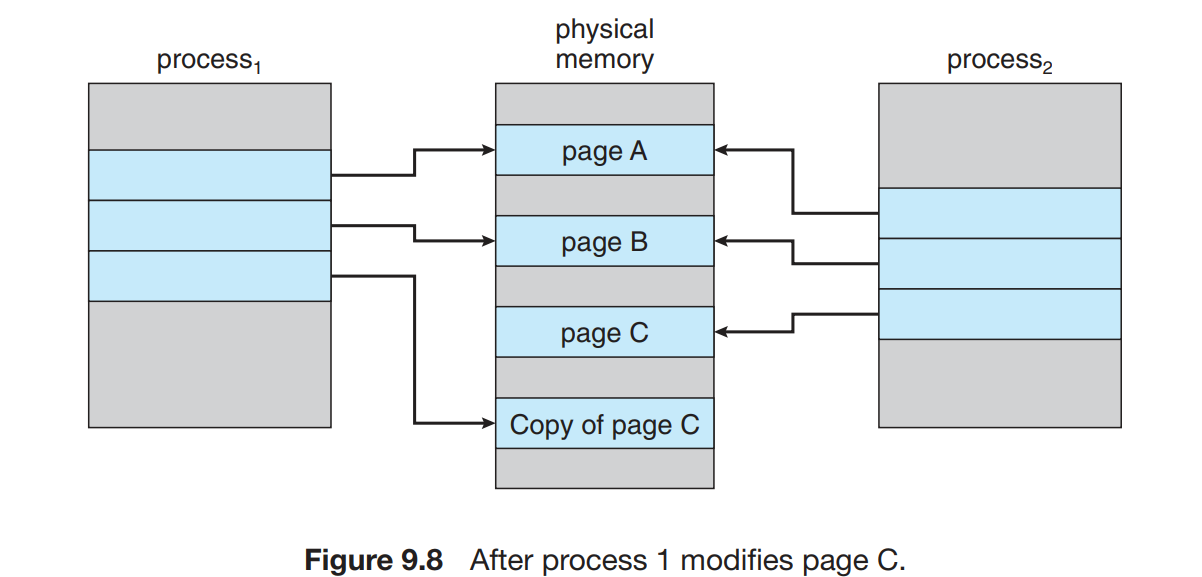
页面置换 | Page Replacement
页面置换是请求调页的基础。下面是内存管理的流程图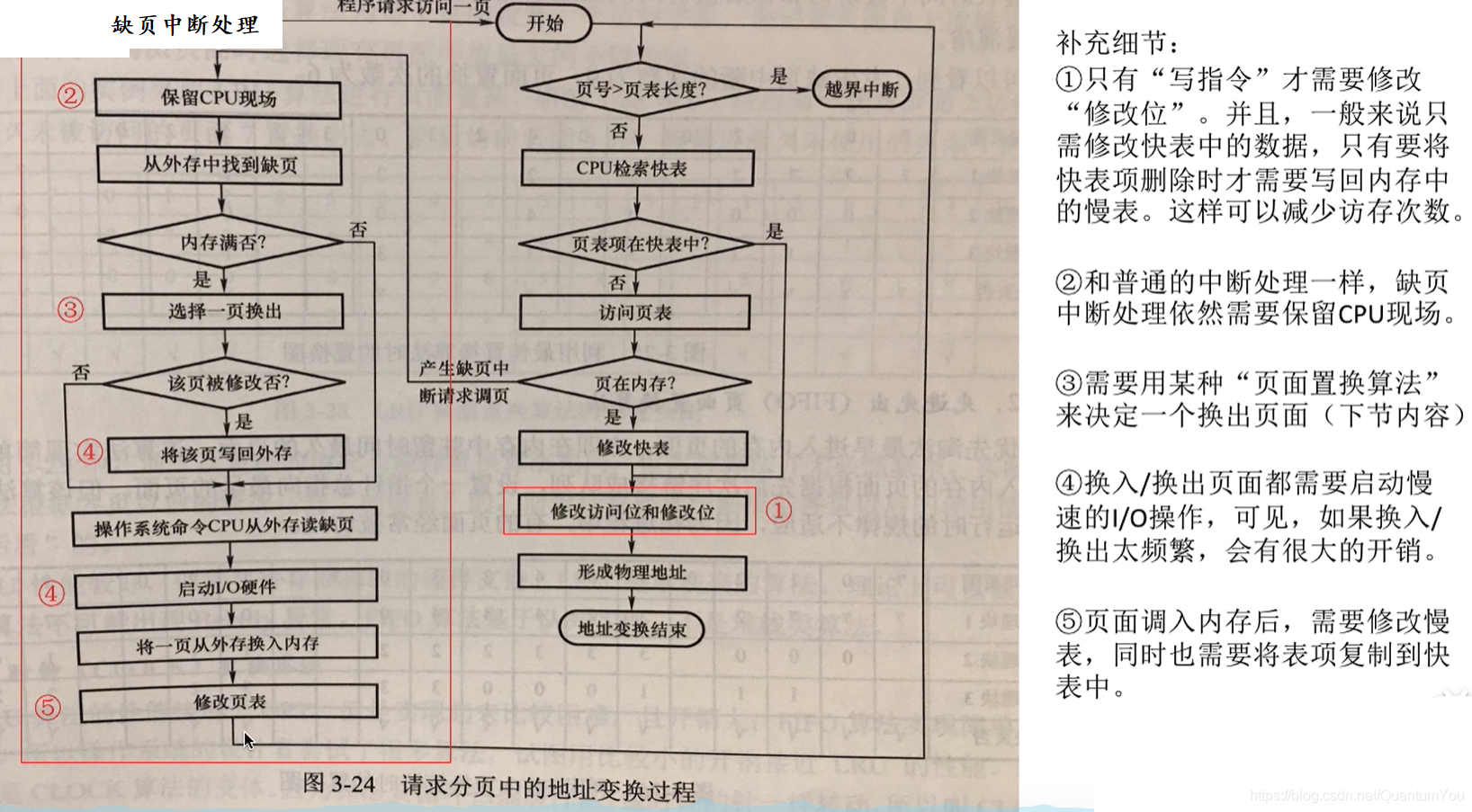
基本页面置换 | Basic Page Replacement
如果没有空闲帧,显然内存需要进行换入换出两个操作,这有点浪费时间了。如这个页面没有被修改过,其实磁盘里面就有该页的备份,所以不需要换出,直接读入就好了,这个标志为就是修改位(modify bit),如果改过了就把该位置1 ,这样把这页换掉的时候就需要传出传入两个操作,否则只需传入就行。
请求调页的时候有两个问题:帧分配算法(frame-allocation algorithm)和页面置换算法(page-replacement algorithm)
下面主要讲解页面置换算法,然后是帧分配算法。
FIFO 页面置换
记录了每个页面调到内存的时间,必须置换页面时,选择最旧的页面,这个置换算法很好理解并且实现,就是个时间队列维护一下,但是这个东西的性能不理想。老旧页面可能是初始化模块,另外一方面可能包含一个大量使用的变量,总之,老旧页面里面可能有重要内容,不能随意丢弃。
最优页面置换 | Optimal Page Replacement
简单的说就是:置换最长时间不会被使用到的界面。
这倒是挺好的, 但是谁也无法在当下预测未来这个页在什么时候调用,所以是理论解。或者引入 ‘串’ 这个未来知识,因此这个东西难以实现,主要用于比较研究。
LRU 页面置换 | LRU Page Replacement
LRU | 最近最少使用算法 这么个奇怪的名字来自于其英文名 (Least-Recent-Used algorithm),简称LRU。这种算法换出 最久没有被访问的页面。
实现的一种策略是给每个页表项一个 counter,每次访问某个 page 时,将 counter 更新为当前的时间。每次需要置换时,搜索 counter 最小的页。也可以用 heap 来优化。
另一种策略是用一个栈保存 page numbers,每次访问时找到它然后把它挪到栈顶。
近似 LRU 页面置换 | LRU-Approximation Page Replacement
很少有操作系统支持真正的 LRU 算法,因为不提供支持,很多操作系统只能用 FIFO 算法,也有操作系统通过 引用位(reference bit) 提供一定形式的支持,但是都不能支持真正的 LRU 算法 。
没有硬件支持,你破解个屁啊!—— 流浪地球
所以才有了近似 LRU 算法
额外引用位算法 | Additional-Reference-Bits Algorithm
因此,我们在 LRU 和性能之间做一个折中;引入一个 reference bit,来近似地实现 LRU。当一个 page 被访问时这个 bit 被置为 1;操作系统定期将 reference bit 清零。因此,在需要交换时,只需要找一个 reference bit 为 0 的就可以说明它在这段时间内没有被访问过。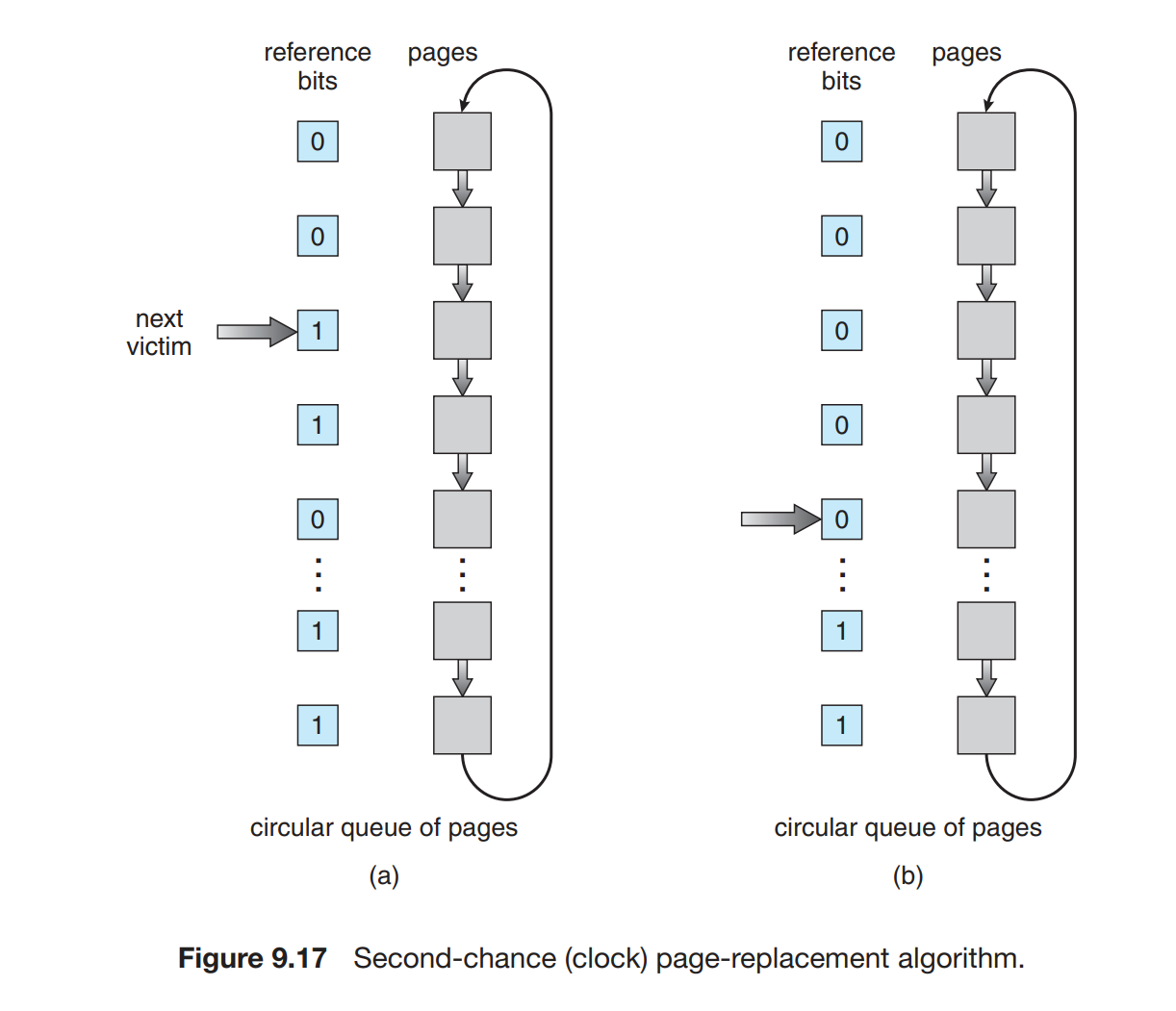
第二次机会算法 | Second-Chance Algorithm
FIFO 的进阶算法,就是 FIFO 算法要清除的时候检查一下 reference bit ,如果为0直接置换,为 1 就再给一次机会,第二次检查到还为 1 就进行替换。也叫时钟算法(clock algorithm)
增强型第二次机会算法 | Enhanced Second-Chance Algorithm
把引用位和修改位作为有序对,组合有下面四种 (引用位 , 修改位)
- (0, 0)最近没有使用并无修改的页面,换掉最没心理负担
- (0, 1)最近没用过但是改过的页面,换的时候要写出
- (1, 0)用过但没修改过,可能马上又要用
- (1, 1)用过修改过,马上又要用,换出又要写磁盘,最麻烦的就是这个
总结:用这种方式给了个优先级计数的页面置换 | Counting-Based Page Replacement
最不经常使用 | Least Frequency Used , LFU
用的多的引用次数多,用的少的引用的少,但是会存一个大数在内存里,不需要了也存着,不是很好。最经常使用 | Most Frequency Used, MFU
上面的问题在于,具有最小计数的页面可能刚刚引入尚未使用。但是实现困难,和最优算法 OPR 的实现难度没啥区别,没啥人用。帧分配 | Allocation of Frames
帧分配这件事,主要是进程之间抢固定数量的且相对稀缺的可用物理内存。页是虚拟的,但是帧是真实的。帧的最小值 | Minimum Number of Frames
实际上,最小值是由具体的计算机架构决定的。我们之前提到,指令在解决其涉及的全部 page fault 之后才能真正被运行;因此每个进程分配的 frame 的最小值不应小于单个指令可能使用到的 frame 总数。
例如,如果可能使用的 frame 数最大的这个指令,其本身不会跨越 2 个 page;但其包含两个访问内存的操作数,其中每个操作数访问的内存可能跨越 2 个 page(即,这块数据在一个 page 的末尾和下一个 page 的开头),那么这个架构上运行的进程的 minimum frame number 是 5。
帧的分配算法 | Allocation Algorithms
最简单的方法是每个进程平均分配(equal allocation),小学生来了都会算。93个帧和5个进程,一个进程18个帧,剩下3个当缓冲。
当然还有一种叫做比例分配(proportional allocation)的方式,按照进程大小分配。
当然,实际操作还有进程优先级需要额外帧的加速……等各种复杂情况
全局分配与局部分配 | Global versus Local Allocation
如果我们采取 全局置换 (global replacement),即每次置换时从所有帧中选取一个帧来计算,那么我们就不一定有必要提前规定每个进程最多能够使用多少个 frame
如果我们采取 局部替换 (local replacement),那么我们就需要提前把物理 frame 的资源分配给各个进程。
显然,前者能够提供更好的系统吞吐量,因此也更常用。当然,前者也存在弊端,因为在这种情况下,一个进程的 page-fault rate 就不仅取决于它自己,还取决于其他进程的运行状况。
现在的很多计算机都有多个 CPU,而每个 CPU 都可以比其他 CPU 更快地访问内存的某些部分。如果这种差异比较明显,我们称这种系统为 非均匀内存访问 (NUMA, Non-Uniform Memory Access) 系统。在这种系统下,为了更好的性能表现,前述的分配和调页算法可能更加复杂。
系统抖动 | Thrashing
如果一个进程可用的帧数量比较少(少于其频繁访问的页面数目),那么它会频繁出现 page fault;同一个 page 可能会被频繁地换入换出,以满足运行的要求。这种高度的页面调度活动成为称为 抖动 (thrashing);其调页时间甚至会大于执行时间。
工作集模型 (working set model) 用来确定一个进程频繁访问的页面,保证这些页面不被换出;需要调页时从剩余的页面进行交换。如果频繁访问的页面数已经大于了当前进程可用的页面数,操作系统就应当把整个进程换出,以防止出现抖动现象。
内存映射文件 | Memory-Mapped Files
假设标准系统调用 open read write 顺序读取文件。每个文件都要系统调用和磁盘访问,或将文件I/O作为常规内存访问,允许一部分虚拟内存与文件进行逻辑关联,导致性能提高。
基本机制 | Basic Mechanism
一开始文件访问和页访问没啥区别,按照普通调页操作,然后按部就班的产生却也错误,然后,文件的读写就走内存访问,没用系统的 open 和 write 这些函数,大大加快速度。
内存映射文件的写入不一定是磁盘文件的同步写入,关闭文件的时候,内存映射会写到磁盘里。然后多个进程访问同一个文件啥的,看看第六章的互斥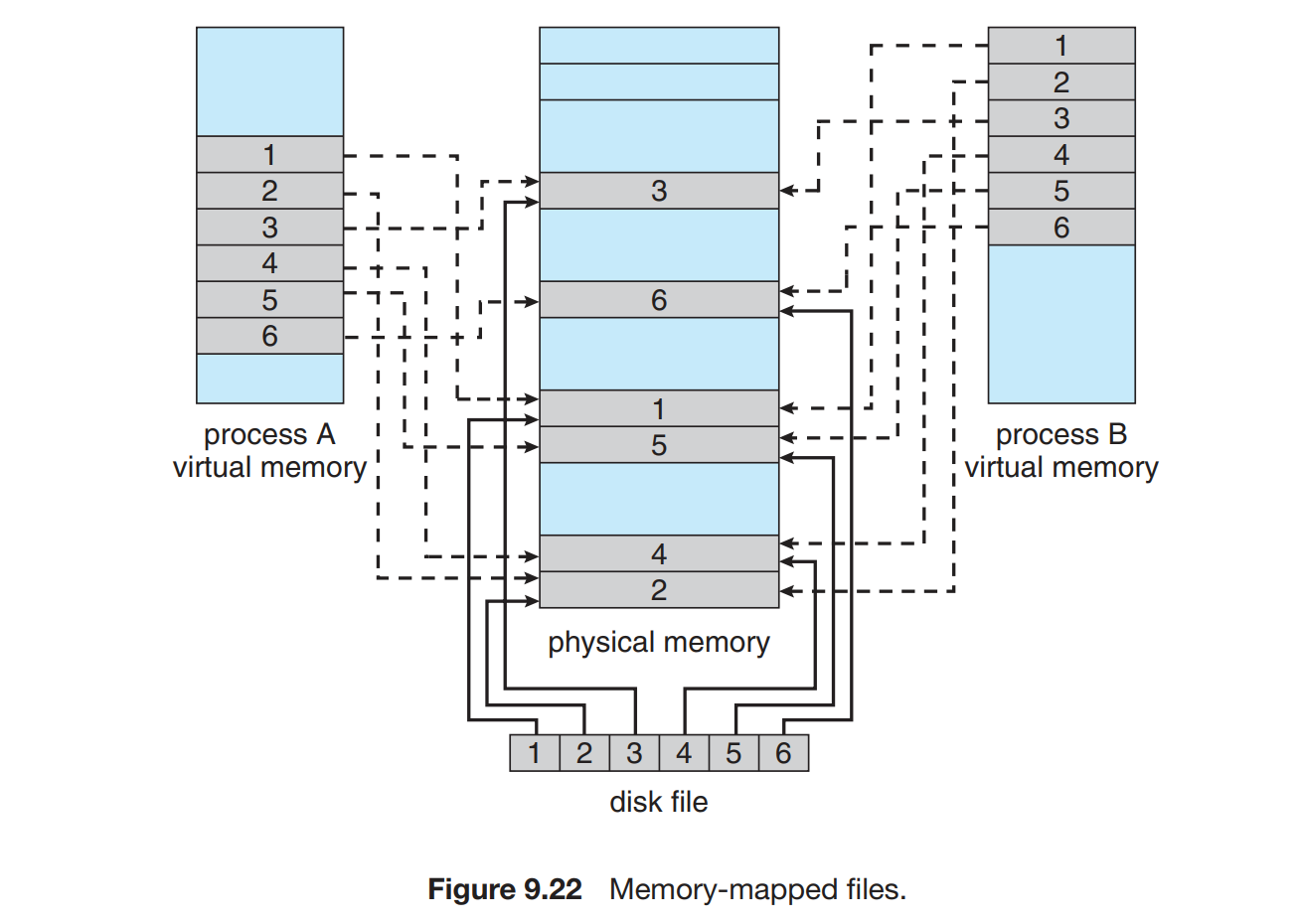
分配内核内存 | Allocating Kernel Memory
Kernel 中的很多数据结构大小区分比较大,其中很多小于甚至远小于一个 page。因此,kernel 的设计应当尽可能节省内存,努力减少碎片。
尽可能减小 kernel 内存开销的考虑是:一方面,kernel 有可能有一部分常驻在物理内存中,不受调页系统的控制;另一方面,有的硬件设备可能和物理内存直接交互,因此可能会需要连续的物理内存。这两者对物理内存的要求都比较严格,因此我们应当尽可能减小这些开销。
伙伴系统 | Buddy System
Buddy system 从物理连续的段上分配内存;每次分配内存大小是 2 的幂次方,例如请求是 11KB,则分配 16KB。
当分配时,从物理段上切分出对应的大小,例如下图体现了分配 21KB 时的情况,分配了一个32KB的内存块。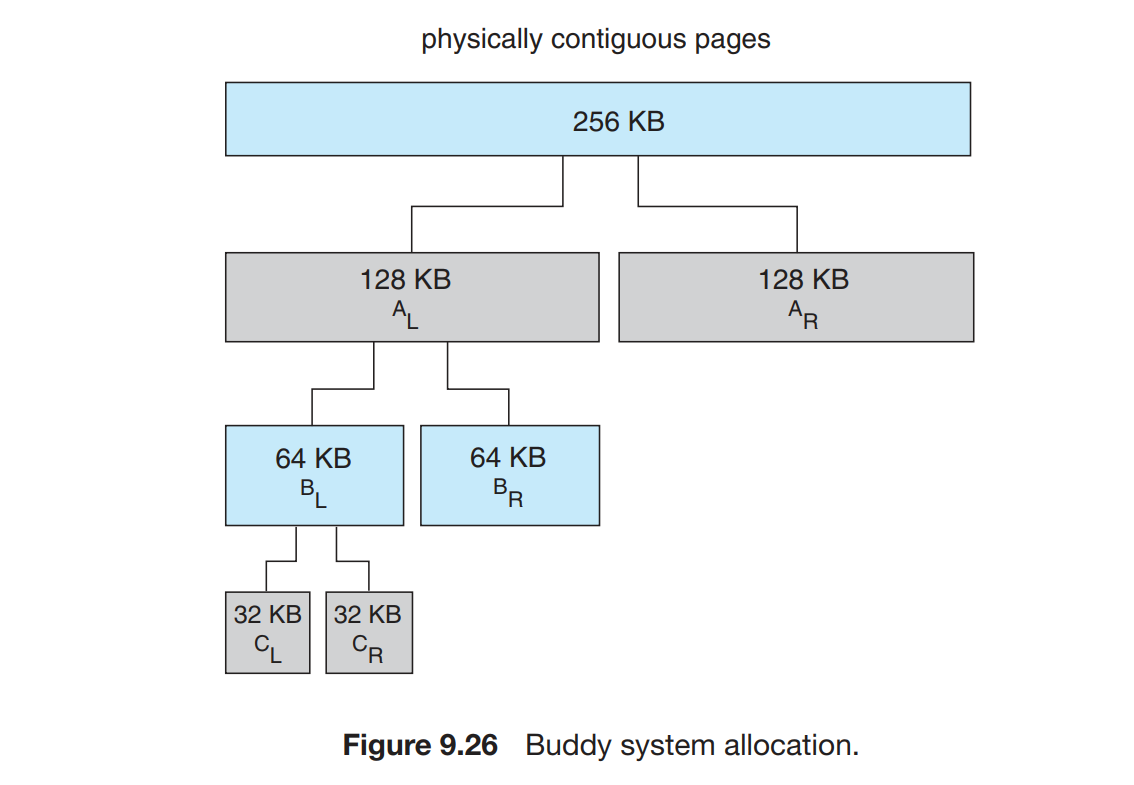
Slab 分配 | Slab Allocation
核心的原理是,操作系统中很多 object 的大小是已知且固定的。内存被划分成若干个固定大小的块,每个块都被分配给一个具体的类型。当进程需要分配内存时,它会查询缓存,如果找到一个空闲的块,就直接使用该块;如果缓存中没有空闲的块,就会从系统内存中申请一个新的块: