
《操作系统概念》第八章笔记 1
背景 | Background
硬件 | Basic Hardware
CPU 根据 PC (Program Counter) 的值从内存中提取指令。CPU 可以访问的通用存储只有内存 & 寄存器,因此想要访问数据,要先移动到内存上。
对 registers 的访问通常可以在一个 CPU 时钟周期中完成,而完成内存的访问可能需要多个时钟周期。在这些时钟周期里,由于没有用来完成指令的数据,这会引起 stall(暂停,抛锚)。为了补救,我们在 CPU 芯片上增设更快的内存,称为 cache (高速缓存)。
确保每一个进程都有单独的内存空间且不相互影响,通过两个寄存器base registers 和 limit register 指定范围的大小。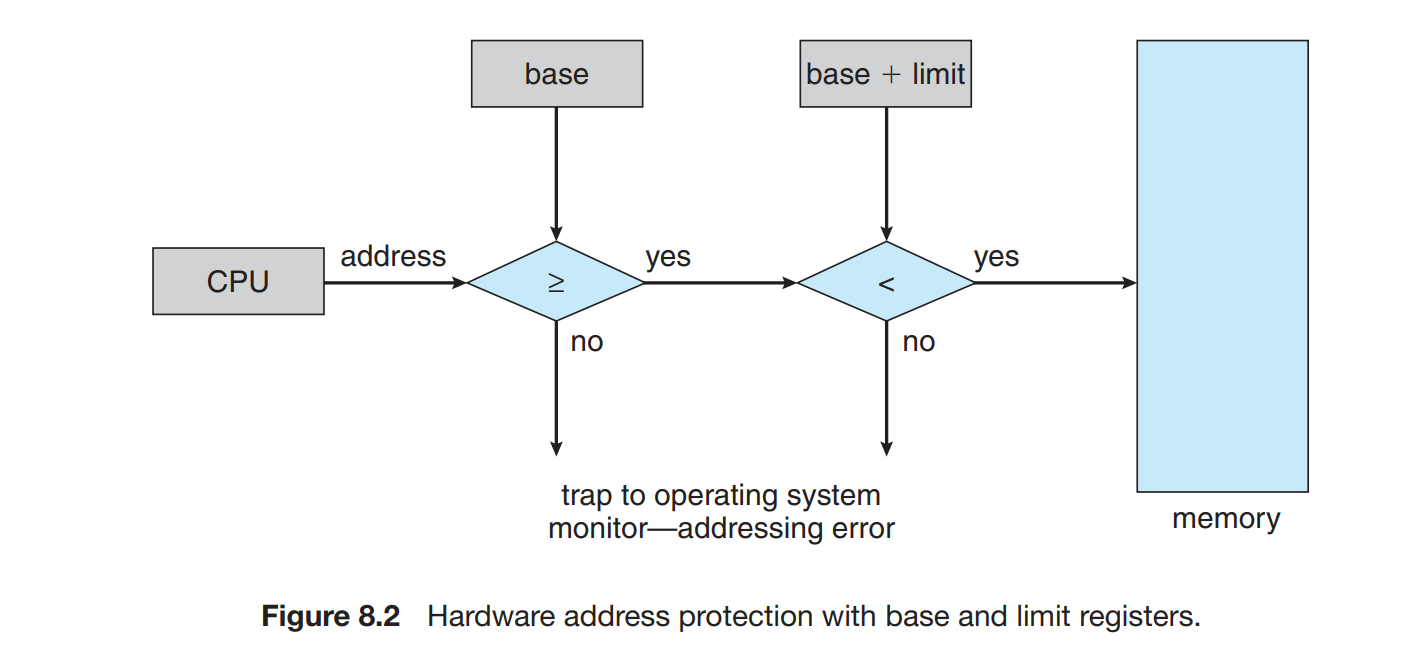
地址绑定 | Address Binding
程序作为二进制文件存放在磁盘上,进程在执行时可以在磁盘和内存之间移动。
源程序中的地址通常是用符号表示(symbolic, 例如各种变量、函数名;汇编中的 label 等);编译器会将其绑定到 relocatable addresses,即相对于某一个段/模块等的偏移。
链接器或加载器(linker / loader)会将 relocatable addresses (可重定位地址)绑定到 absolute addresses。当然,如果编译器在编译时就知道程序所处的内存地址,则会生成 absolute code。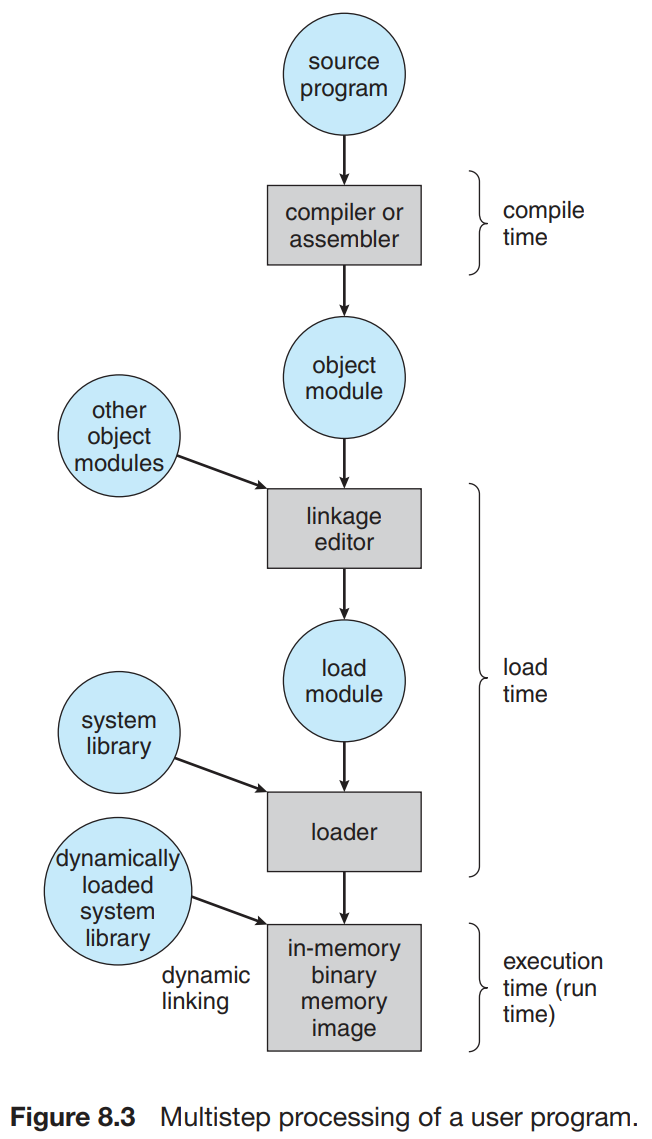
逻辑地址空间与物理地址空间 | Logical Versus Physical Address Space
CPU 生成的地址通常称为逻辑地址,也称为虚拟地址,内存地址寄存器的地址通常称为物理地址。
从虚拟地址到物理地址的映射由内存管理单元来完成,用户程序不会看到真实的物理地址,其过程如下图所示。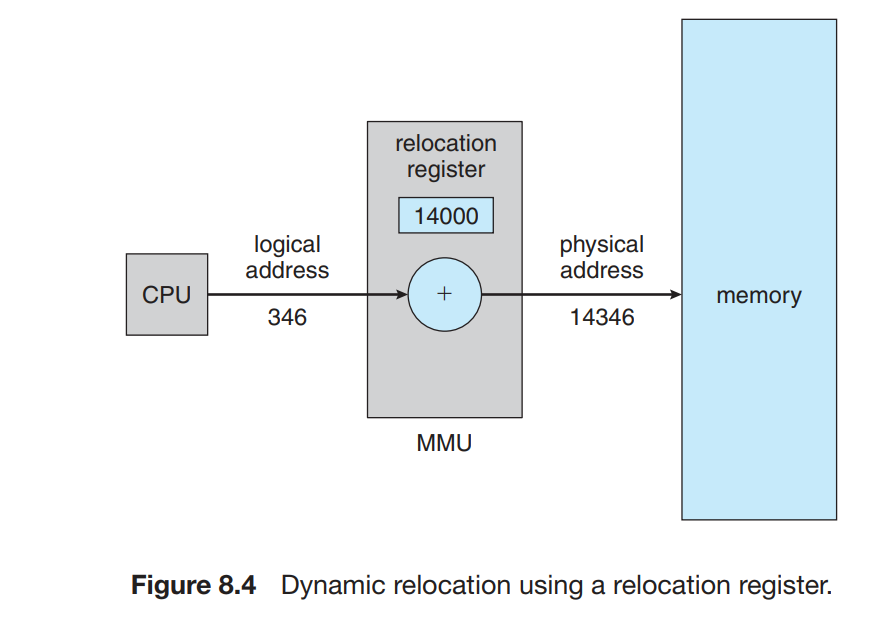
动态加载 | Dynamic Loading
进程的大小受限于内存的大小,为了更好的内存空间利用率,可以使用动态加载
其优点是只要被需要的时候才会被加载。
动态链接和共享库 | Dynamic Linking and Shared Libraries
动态链接库可以称为系统库,可链接到用户程序,以便运行。
动态链接可以用于库的更新,一个库可以被新版本所取代,而且使用该库的所用程序会自动更新。为了不让程序意外执行版本不兼容的库,程序通过版本信息判断加载什么库,这种也称为共享库
交换 | Swapping
进程必须在内存中执行,但是进程是有切换过程的,在挂起时可以暂时从内存交换到备份存储。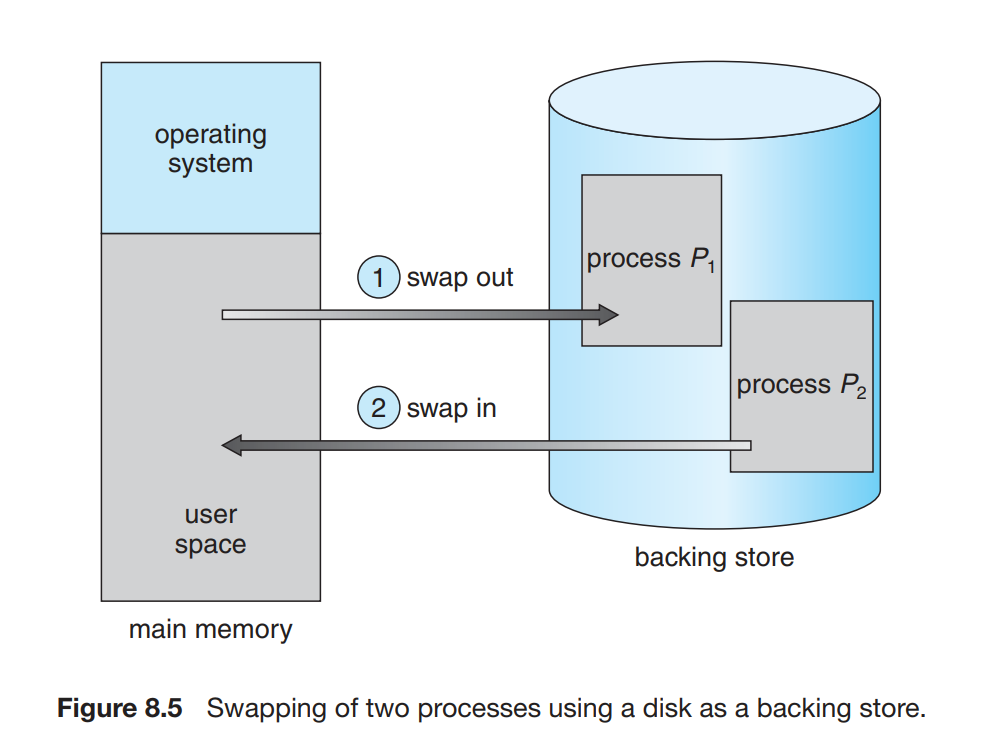
标准交换 | Standard Swapping
标准交换在内存与备份存储之间移动进程,备份存储通常是快速磁盘,足够大。系统维护一个可运行的所有进程的就绪队列。然而现在操作系统并不使用标准交换,交换时间太多,执行时间少,CPU效率低。而是使用交换的变种。
移动系统的交换 | Swapping on Mobile Systems
移动系统通常不支持任何形式的交换,移动系统通常采用闪存,而不是硬盘作为永久存储。安卓在没有自购内存时,可以终止进程,并把当前状态保存到闪存。
连续分配内存 | Contiguous Memory Allocation
内存通常分为两个区域:一个用于驻留操作系统,另一个用于用户进程。在采用连续内存分配时,每个进程位于一个连续的内存区域,与包含下一个进程的内存相连。
内存保护 | Memory Protection
当 CPU 调度器选择一个进程执行的时候,作为上下文切换工作的一部分,分派器会加载重定位寄存器和界限寄存器,保证其他进程不受运行进程的影响。
重定位寄存器提供了有效的方案,允许操作系统动态的改变大小。
MMU相关内容见上。
内存分配 | Memory Allocation
多分区方案:主要用于批处理环境,其他情况已经不再使用
对于可变分区方案,操作系统有一个表,用于记录哪些内存可用和哪些内存已用。
开始时整个内存就是一大块可用的内存块(将可用内存块称为 hole);经过一段时间的运行后,内存可能会包含一系列不同大小的孔。下图是一个示例。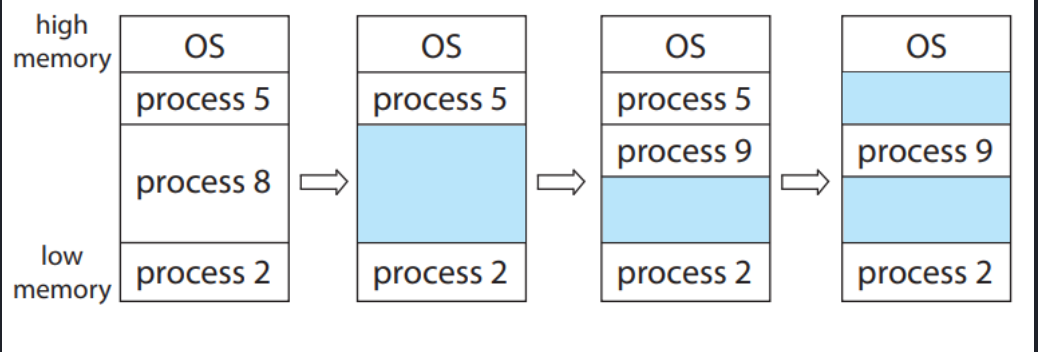
很可能在进行一段时间的运行后,空闲内存空间被分为大量的 hole,它们总体加起来可以满足进程要求,但它们并不连续,每一个小的 hole 都不可以被利用。我们称这种问题为 External Fragmentation,因为这些不可用内存是分布在 partition 之外的。
分配的方式如下
- 首次适应 | first-fit : 分配首个足够大的孔。这种方法会使得分配集中在低地址区,并在此处产生大量的碎片,在每次尝试分配的时候都会遍历到,增大查找的开销。
- 最优适应 | best-fit : 分配最小的足够大的孔,除非空闲列表按大小排序,否则这种方法需要对整个列表进行遍历。这种方法同样会留下许多碎片。
- 最差适应 | worst-fit : 分配最大的孔。同样,除非列表有序,否则我们需要遍历整个列表。这种方法的好处是每次分配后通常不会使剩下的空闲块太小,这在中小进程较多的情况下性能较好,并且产生碎片的几率更小。
分段 | Segmentation
虽然我们程序中的主函数、数组、符号表、子函数等等内部需要有一定的顺序,但是这些模块之间的先后顺序是无关紧要的。因此,虽然实际上内存是一个线性的字节数组,但是在用户看来,一个程序长成这个样子: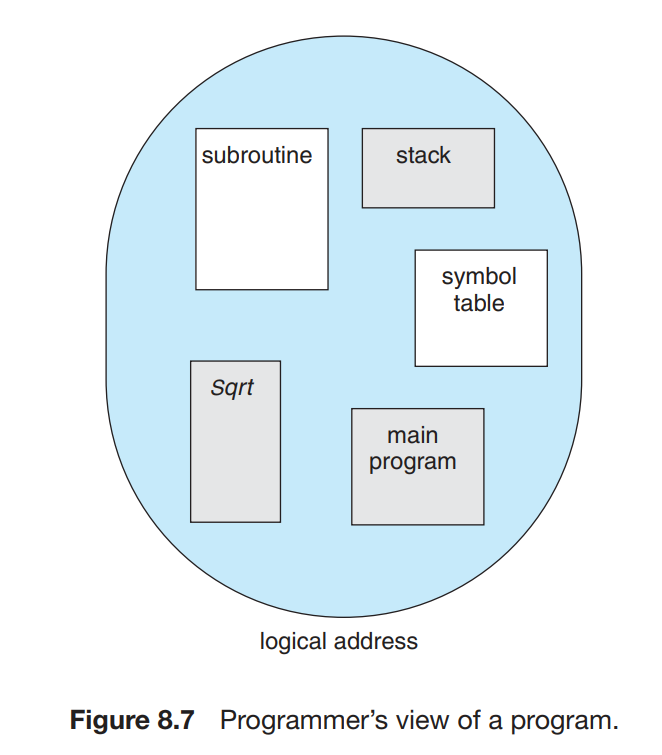
即,一个程序是由一组 segment (段)构成的,每个 segment 都有其名称和长度。我们只要知道 segment 在物理内存中的基地址 (base) 和段内偏移地址 (offset) 就可以对应到物理地址中了。对于每一个 segment,我们给其一个编号。即,我们通过二元有序组 表示了一个地址。这种表示称为 logical address(逻辑地址)或 virtual address(虚拟地址)。
分段硬件 | Segmentation Hardware
段表的每个条目段基地址(segment base) 和 段界限(segment limit) 段基地址包含该内存中开始的物理地址,段界限指定该段长度。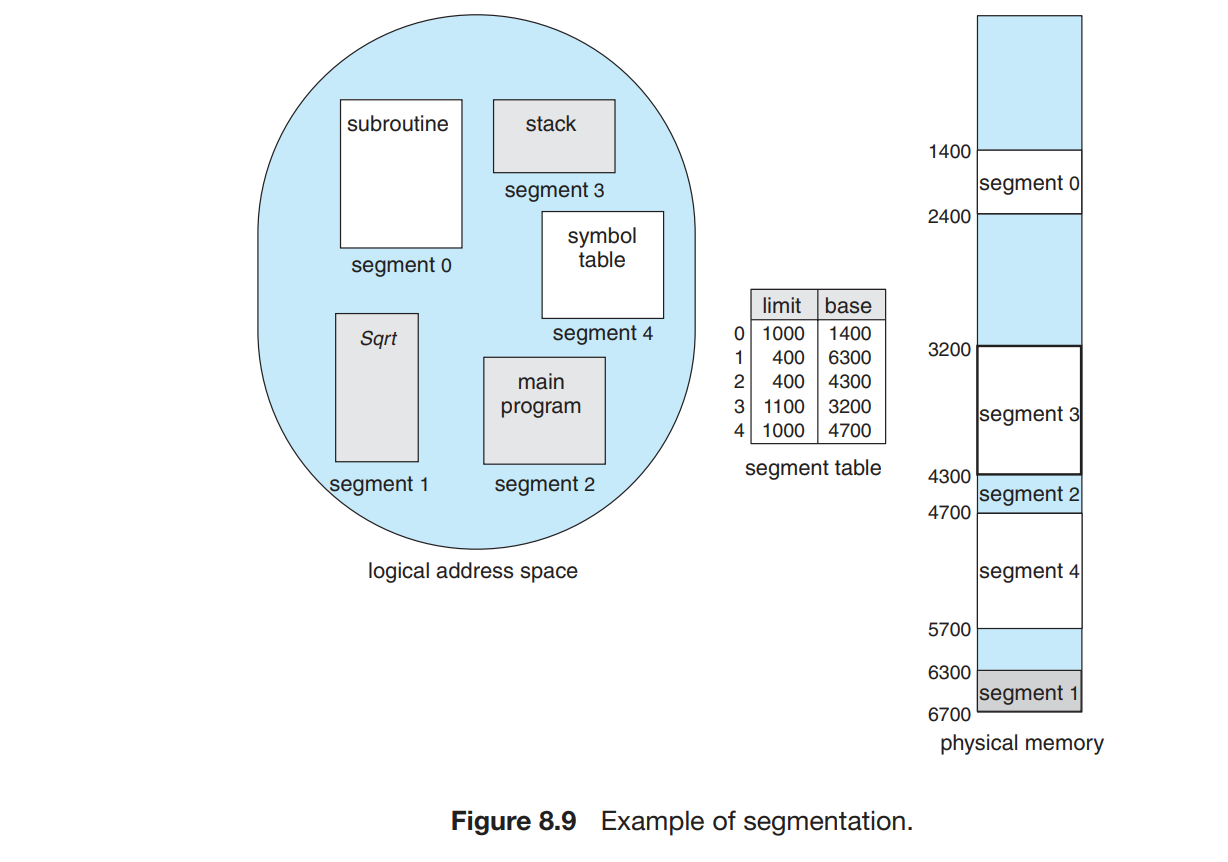
分页 | Paging
分页避免了外部碎片和紧缩,而分段不可以。分页也避免了将不同大小的内存块匹配到交换的麻烦问题。
基本方法 | Basic Method
我们将物理内存切分成等大小的块(2 的幂,通常为 4KB = 2^12B),称为 frames(帧)。将逻辑内存切分成同样大小的块,称为 pages(页)
当一个进程要执行时,其内容填到一些可用的帧中,其中的每一个地址可以用这个 帧的基地址或 数字(由于 frame 是被等大切分出来的,因此每个 frame 的基地址也唯一对应一个 frame number)以及相对这个基地址的偏移表示。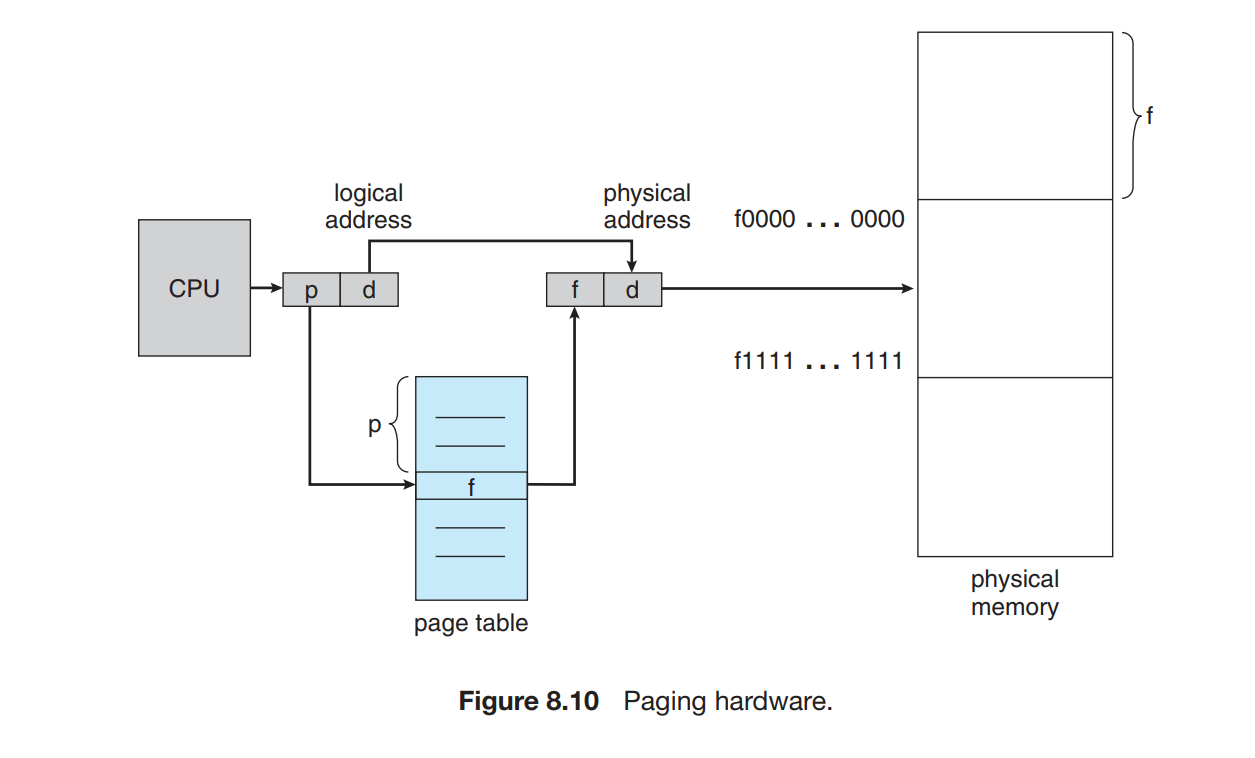
当 MMU 需要将一个逻辑地址转换为物理地址时,它需要获取 page number p,在 page table(页表)中找到第 p 个 page 对应的的 frame number(也就是 frame base) f ,在 f 后面连接上偏移 d 就得到了对应的物理地址。如前所说,逻辑地址和物理地址的偏移应是一致的。
在页表中,我们用逻辑地址的连续代替了物理地址的连续。然而,逻辑地址到物理地址的映射是由操作系统控制的,并不受程序员控制。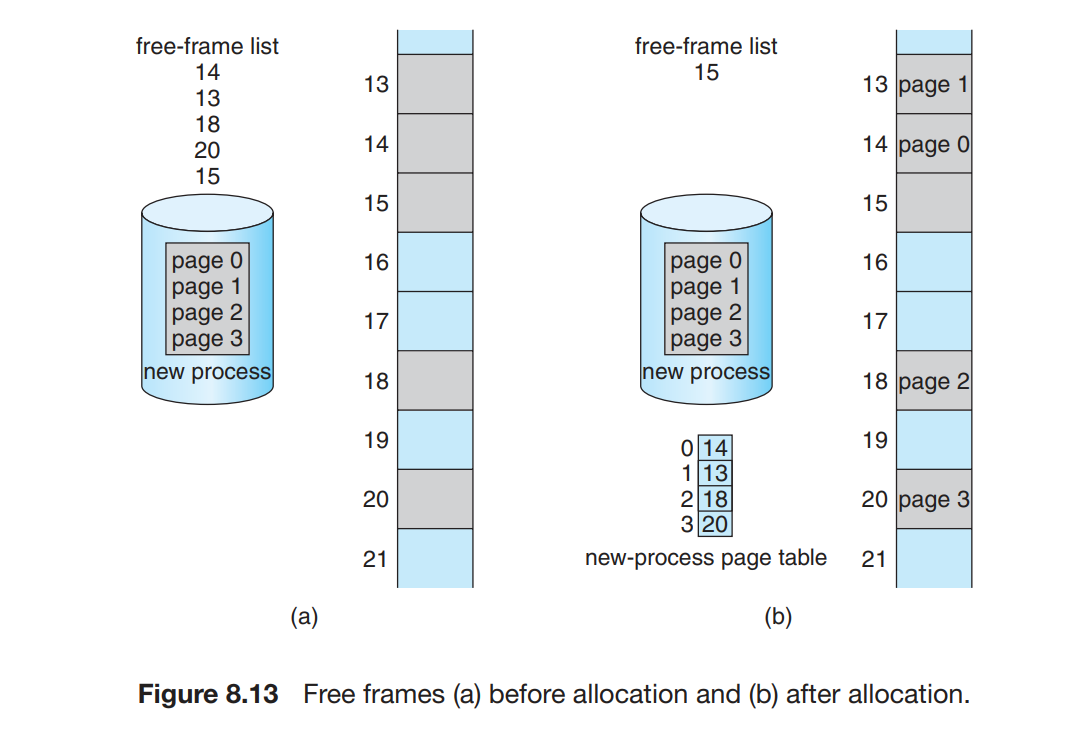
硬件支持 | Hardware Support
Page table 是每个进程都有一份的结构,其硬件实现有多种方法。
寄存器 | Register
这一实现方法的优点是使用时非常迅速,因为对寄存器的访问是十分高效的。但是,寄存器的数量有限,因此这种方法要求 page table 的大小很小;同时,由于专用寄存器只有一组,因此上下文切换时需要存储并重新加载这些寄存器。
页表基地址寄存器 | Page-Table Base Register
把页表放在内存中,并将页表基地址寄存器指向页表,改变页表只需要改变这一个寄存器就行,降低了上下文切换的时间。
但是这种方法的效率存在问题。要访问逻辑地址对应的物理地址,我们首先要根据 PTBR 和 page number 来找到页表在内存的位置,并在其中得到页对应的 frame number,这需要一次内存访问;然后我们根据 frame number 和偏移算出真实的物理地址,并访问对应的字节内容。即,访问一个字节需要两次内存访问,这会加倍原本的内存访问的时间,这是难以接受的。
转换表缓冲区 | Translation Look-aside Buffer
这个问题的解决方法用到一个专用的高速查找硬件 cache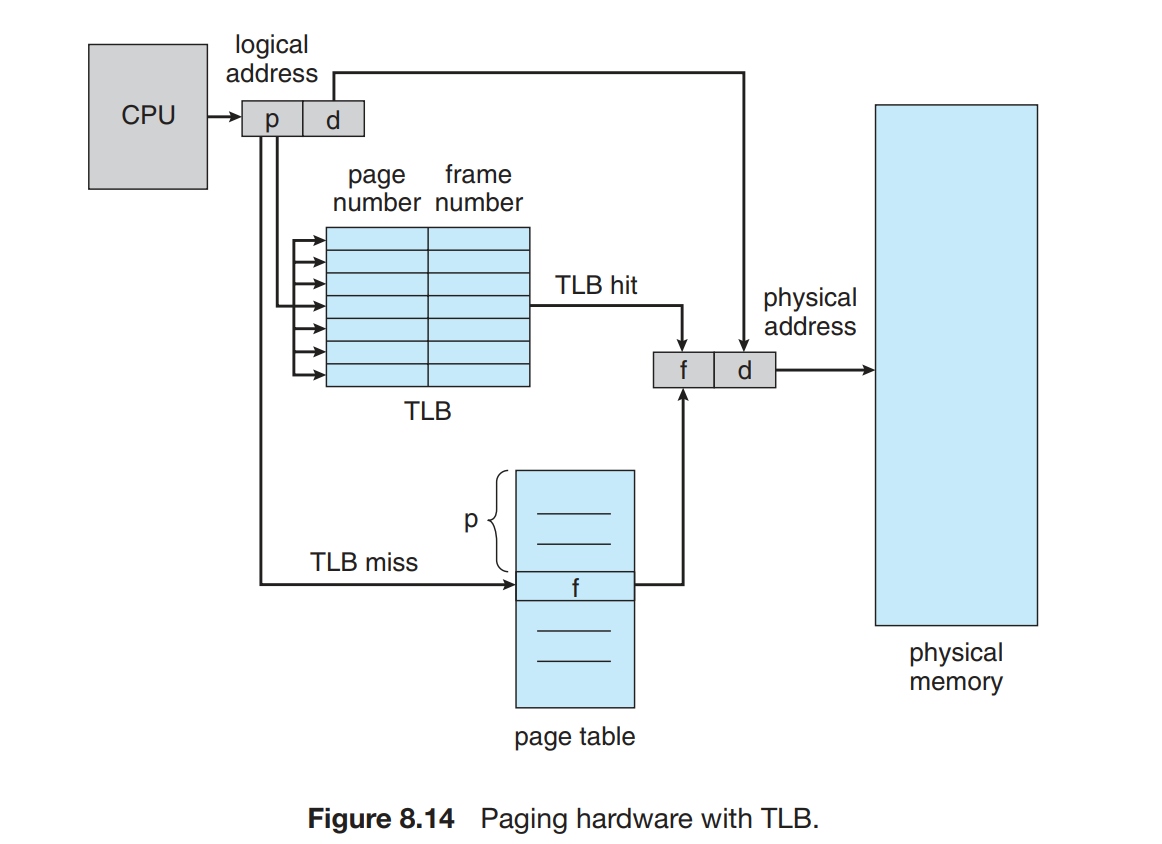
当我们需要找到一个 page number 对应的 frame number 时,TLB 会 同时 与其中所有的 key 进行比较:如果找到对应条目,就不必访问内存;如果没有找到(称为 TLB miss),则访问内存并将新的 key & value 存入 TLB 中,这会替换掉 TLB 原有的一个条目。
地址空间标识符 | Address-Space Identifier
每个 process 都有其自己的 page table。因此切换进程时也需要切换 page table。亦即,我们需要保证 TLB 与当前进程的 page table 是一致的。为了保证这一要求,我们可以在每次切换时 刷新(flush) TLB。
有些 TLB 还在每个条目中保存 Address-Space Identifier (ASID),每个 ASID 唯一标识一个进程。当 TLB 进行匹配时,除了 page number 外也对 ASID 进行匹配。
保护 | Protection
分页环境下内存保护通过与每个帧关联的保护位实现,这些位保存在页表中。比如: valid-invalid bit(有效-无效位)
当该位是有效时,表示相关的页在进程的逻辑地址空间内,因此是合法的位。操作系统通过对该位的设置,可以允许或不允许对某页的访问。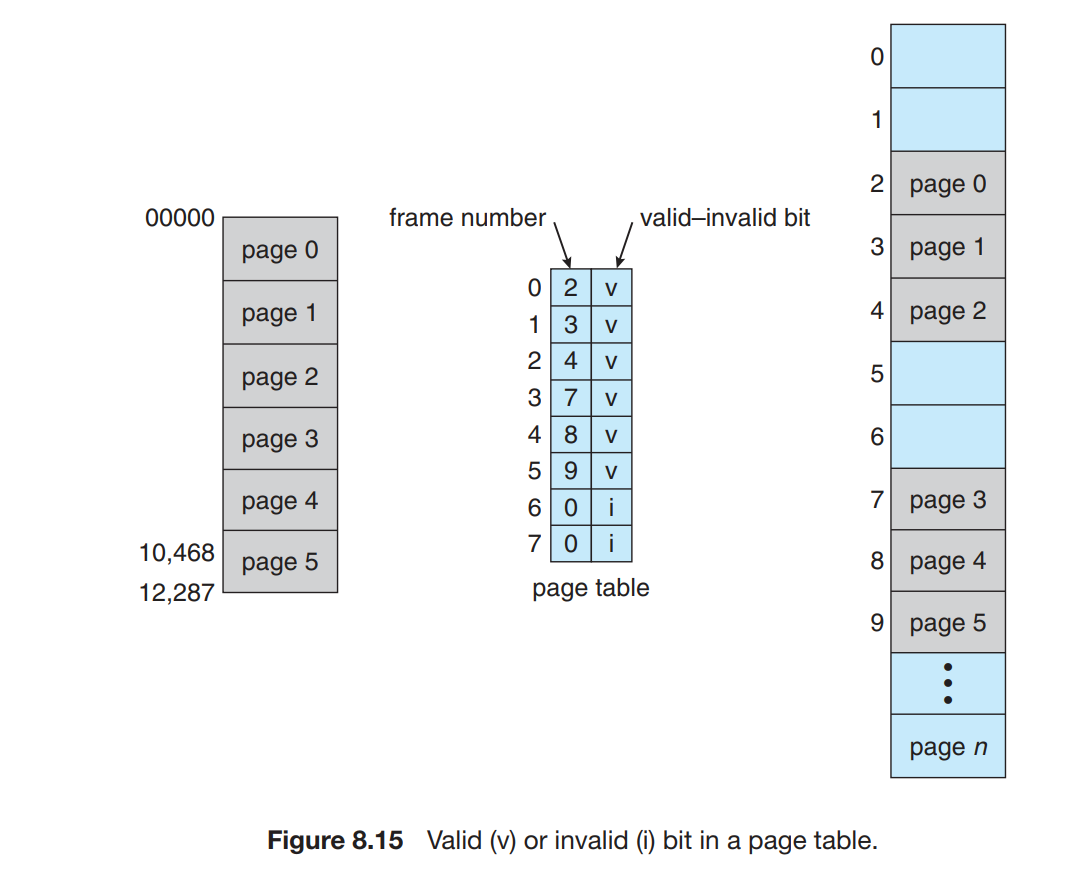
一个进程很少使用它的所有地址空间,事实上,很多进程只使用页的一小部分,对于这种情况,有的系统提供 页表长度寄存器 来表示页的大小。
共享页 | Shared Pages
分页可以允许进程间共享代码,例如同一程序的多个进程可以使用同一份代码,只要这份代码是可重入代码(reentrant code)或者 非自修改代码 (non-self-modifying code)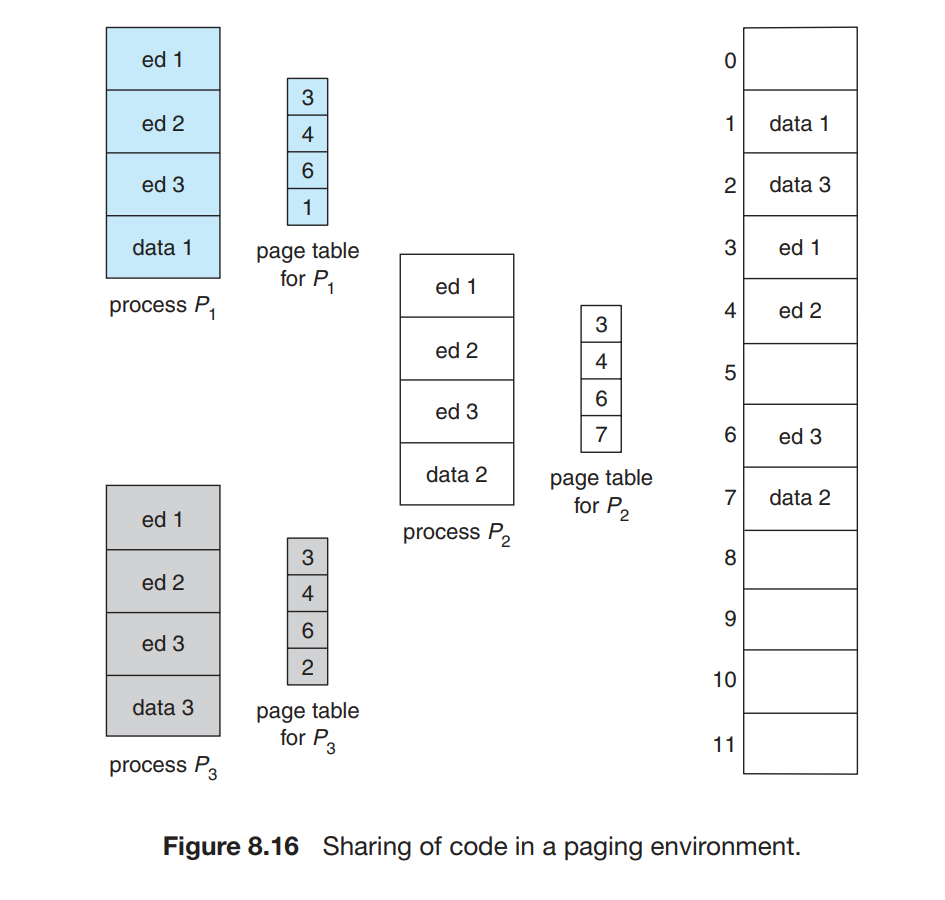
图中所述的是多个进程共享一份库代码的情况;共享还可以用于进程之间的交流。当然,每个进程也可以有其自己的代码和数据。
页表结构 | Structure of the Page Table
分层页表 | Hierarchical Paging
页表是一个数组, page_table[i] 中存储的是 page number 为 i 的 page 所对应的 frame number。考虑我们的逻辑地址结构: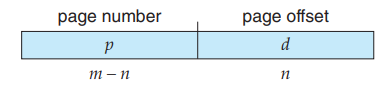
这样的逻辑地址结构需要一个存储 2^p 个元素的 page table,即需要这么大的连续内存,这是非常大的消耗。我们考虑将 p 再分为 p1 和 p2 :
我们使用一个两级页表, outer_page_table[i] 中存储的是 p1 为 i 的 inner page table,即inner_page_table[i][] 的基地址;而 inner_page_table[i][j] 中存储的就是 p1 为 i,p2 为 j 的 page 对应的 frame number,即 page number 为 p1p2 (没有分割时的 p)对应的 frame number。
逻辑地址 代替 物理地址满足了程序的连续要求。考虑这中分两页的 page table 结构,我们可以发现我们只是将 p 分成了两部分;对于程序来说,p+d 构成的整体(即逻辑地址)仍然是连续的,而且程序并不会意识到我们将 p 分成了 p1 和 p2 两部分,就像曾经它没有意识到我们将地址分为了 p 和 d 两部分一样。这些划分只是我们为了更好地分配内存所做的、操作系统层面 的事情而已。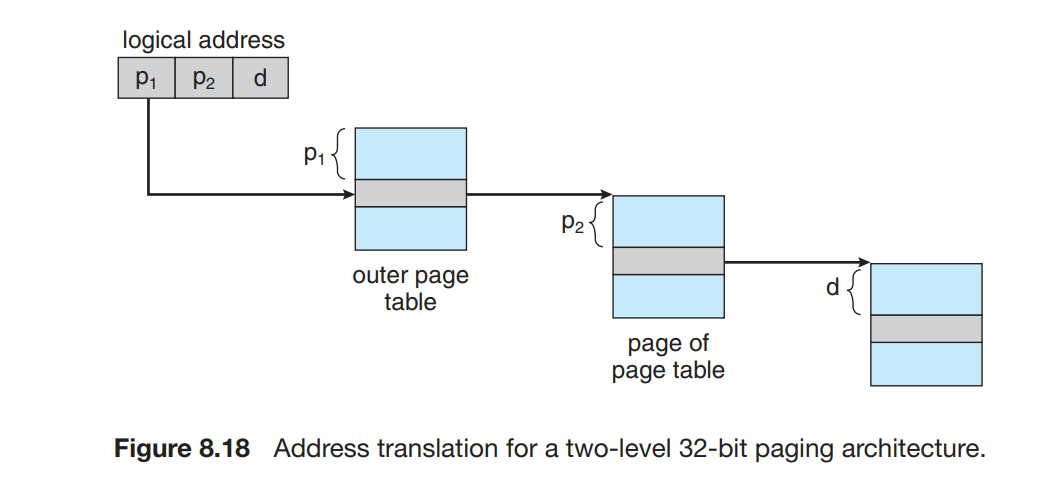
另外,这样做在一般情况下可以节省空间。我们之前提到,页表不一定会全部使用;并且由于逻辑地址是连续的,因此用到的页表项也是连续的,都排在页表的头部。因此如果我们采用了二级页表,那么许多排在后面的内页表将完全为空;此时我们可以直接不给这些内页表分配空间,即我们只分配最大的 p1多个 inner page table。这样我们可以节省很多空间。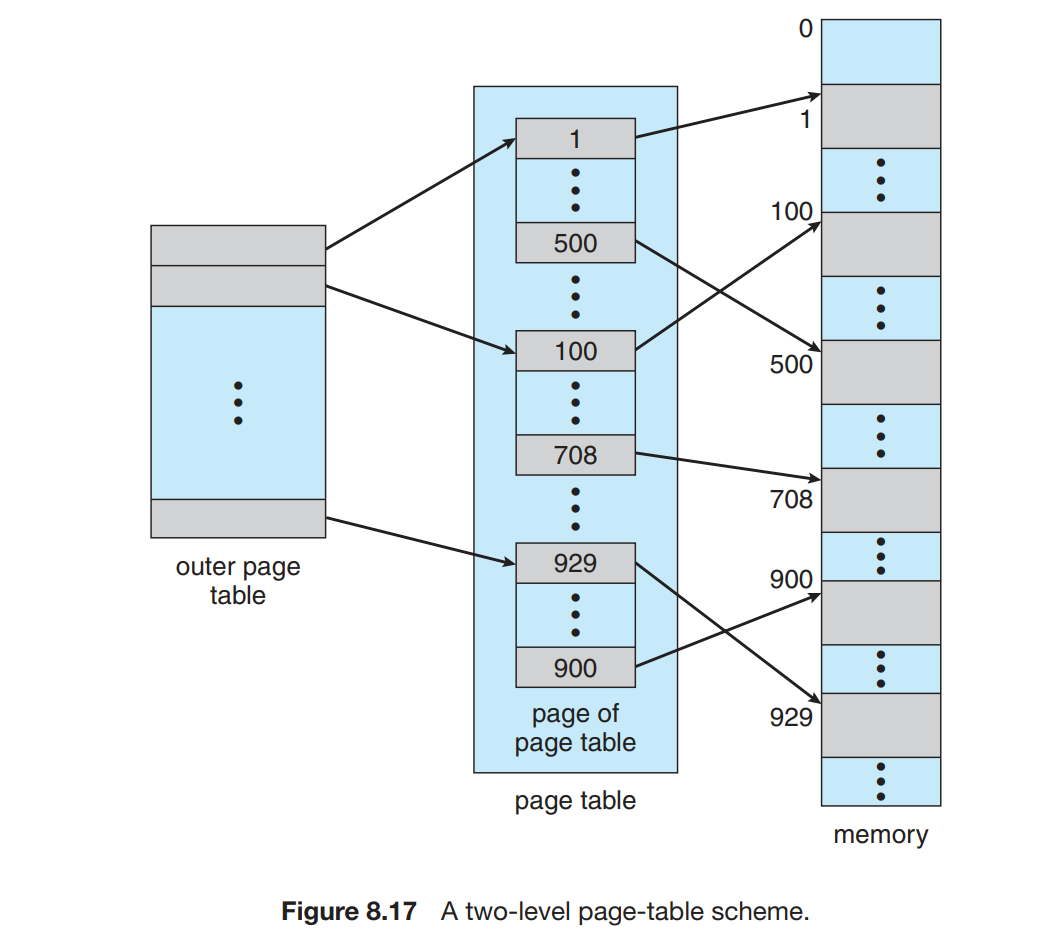
类似地,我们可以设计更多级的页表。例如:
哈希页表 | Hashed Page Tables
处理大于32位地址空间的常用方法是哈希页表,哈希页表的每个条目包括一个链表,该链表的元素哈希到同一个位置(处理哈希碰撞)。
每个元素由三个字段组成:虚拟页码,映射的帧码,指向链表的下一个元素的指针。
虚拟页码哈希到哈希表,用虚拟页码与链表的以一个元素比较(确认哈希冲突),如果匹配,第二个字段就是用来形成物理地址,不匹配,就一直找。
省流:哈希表存储,用的时候找到对应页表算物理地址。上面说了一大串就是个哈希查找的过程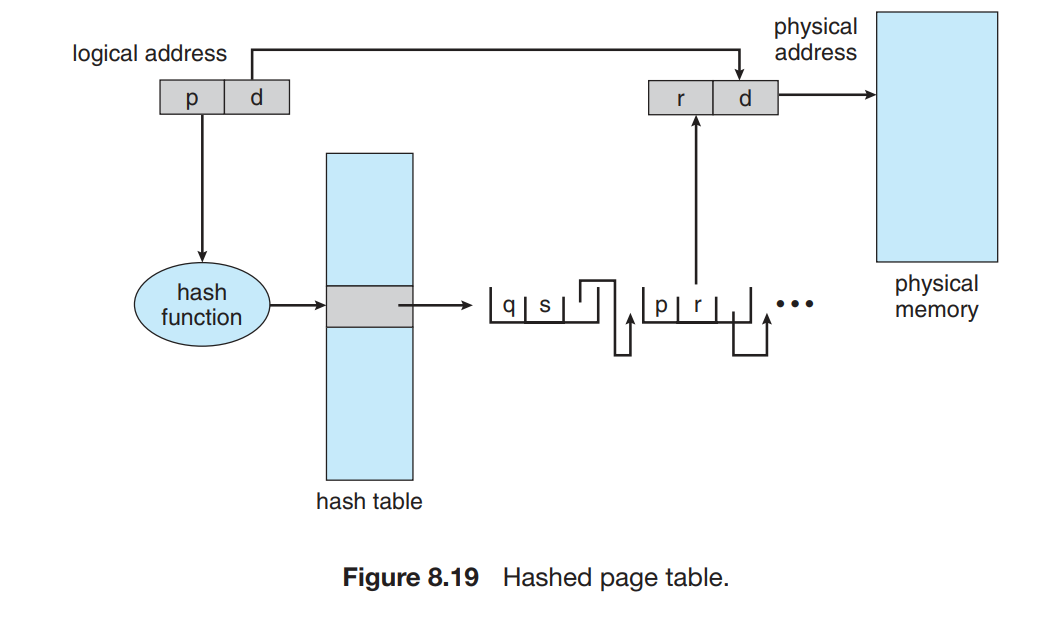
倒置页表 | Inverted Page Tables
在之前的分页方法时,每个进程都有一个页表。这种方法会导致这些表可能使用大量的物理内存。
倒置页表的索引物理地址而不是虚拟地址,也就是说,整个系统只有一个页表,并且每个物理内存的帧只有一条相应的条目。寻址时,CPU 遍历页表,找到对应的 pid 和 page number,其在页表中所处的位置即为 frame number:
这种做法的缺点是,寻址过程需要很长时间。我们也可以用 TLB 或者 hashed table 来加速。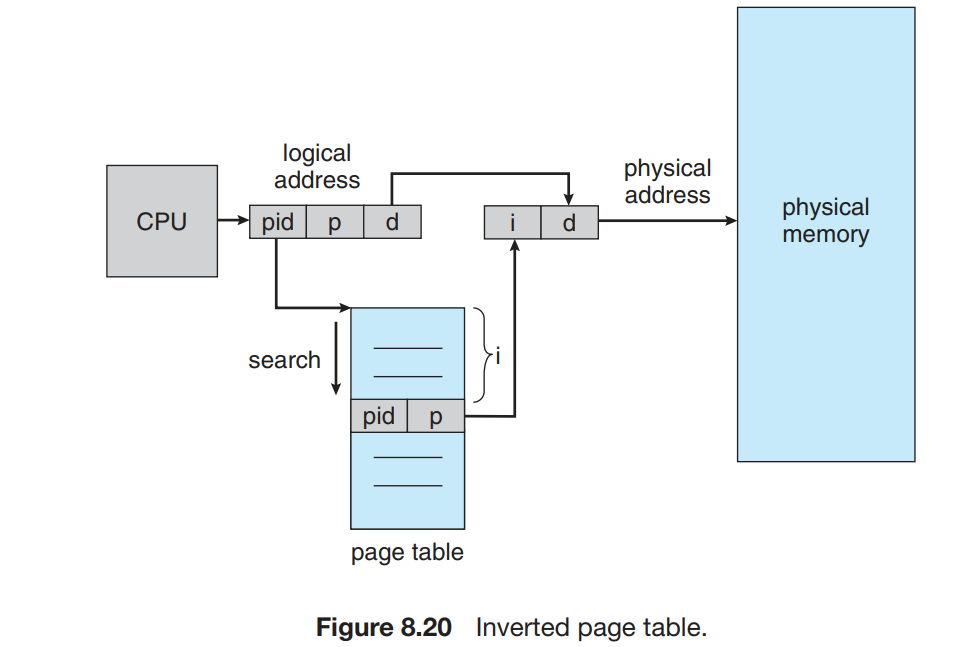
另外一个问题是,这种方法不能够共享内存,因为 page table 的每一个条目(与 frame number 一一对应)只能存储一个 page number。
(懂不懂什么是倒排索引表啊!仰头)




